I have use cases where support for some simple tables would be nice. Or at least some sort of column layout. I.e. each line of a lyric may not be very long and I could get more on one screen if I could put the 1st verse on left and 2nd verse on the right.
Other use cases would be to have the lyrics/chords on left and some other notes on the right.
Interesting - I hadn’t considered that kind of layout. Let me think about it. In any case it’s a higher level construct than what I’m trying to solve right now.
That’s just a function of my test program where I can increase the size of the font’s being used so it’s technically not a zoom. Still it’s an interesting point but makes me wonder what you might really want here as far as show notes is concerned:
The ability to zoom the entire show notes panel. or
The ability to quickly increase the size of a particular element in the show notes?
My plan was to integrate this new text rendering support into Cantabile with the goal of just fixing the current issues with text rendering.
However I was a little concerned about the performance and memory usage of some of the code I ported from other source. On closer inspection, I’m really not happy with the Bidi algorithm that I ported from the Unicode’s reference implementation. It does the job, it seems fast enough, but it’s terrible as far as memory management is concerned. Given how much and how often Cantabile needs to draw text it might have an impact on memory usage and put extra pressure the garbage collector.
So I need a better implementation and after spending all morning looking for one, there just doesn’t seem to be that fits all the requirements. It looks like I might need to write it myself which isn’t a trivial task - probably about a week’s work - the spec is over 40 printed A4 pages.
I don’t know if this is a path I want to take. I’ll read the spec again before making a decision .
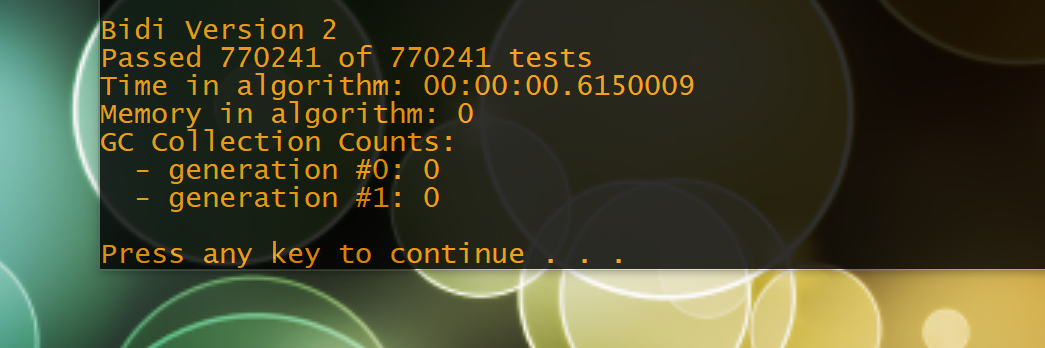
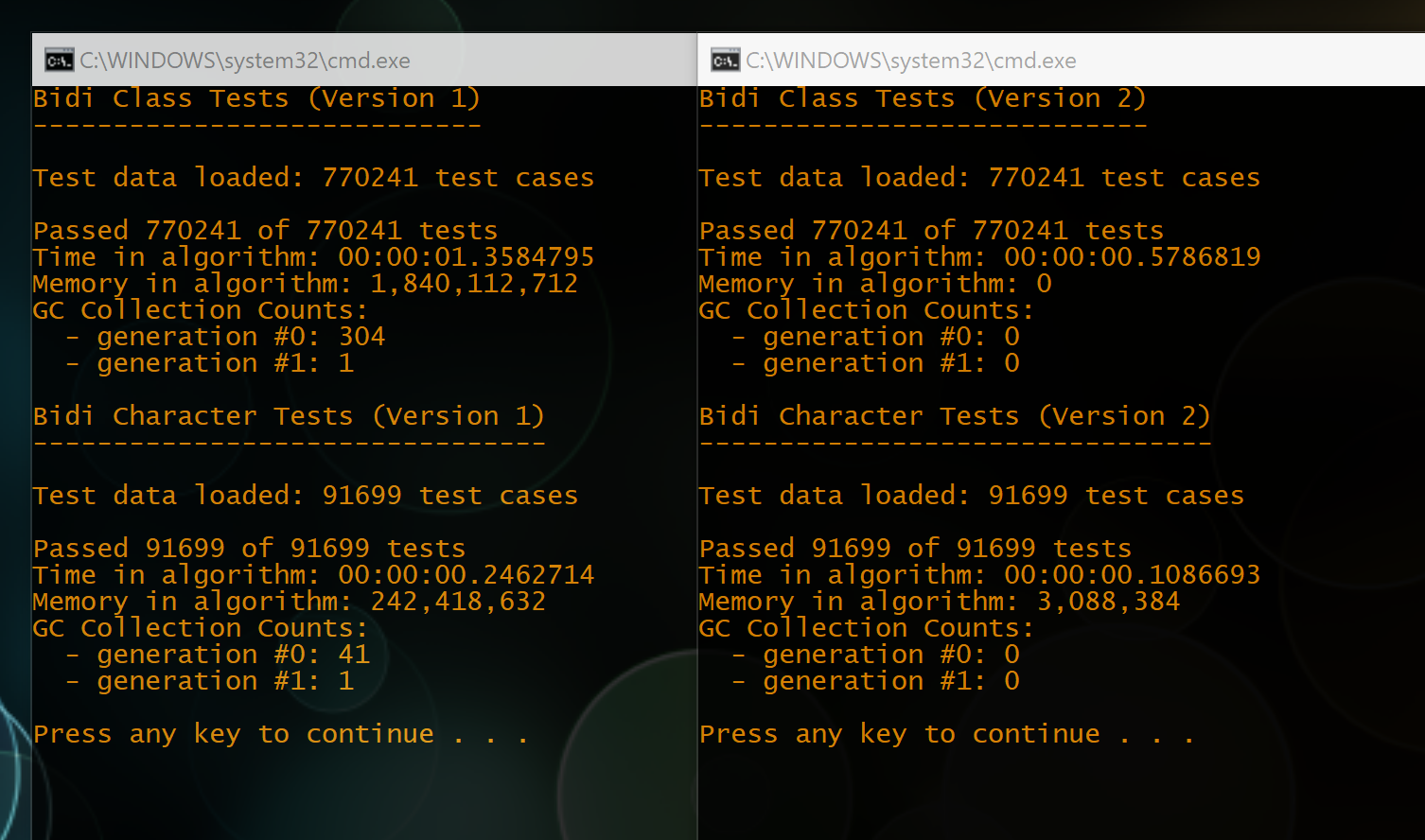
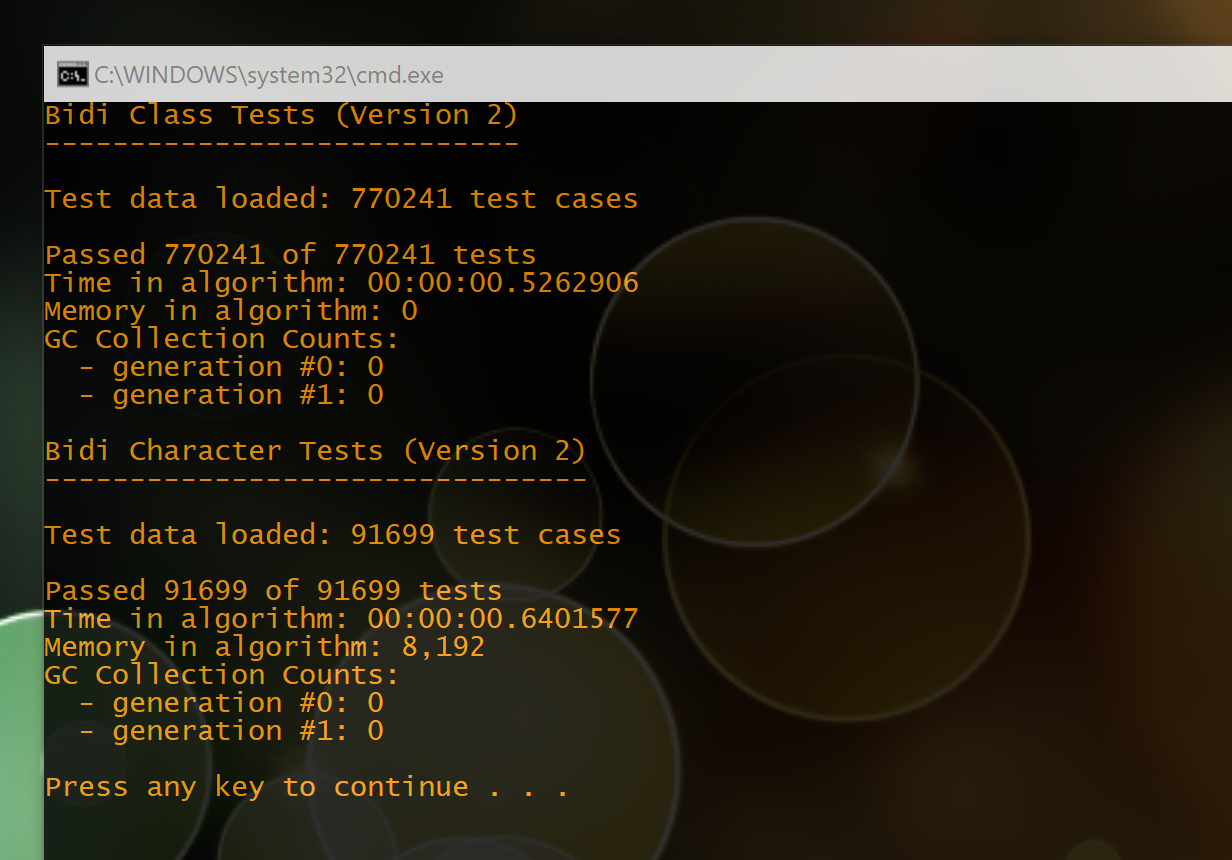
Fixed a couple of minor bugs and the new implementation now passes the final 90k test cases. Also, it’s more than twice as fast as the old routine for the same data.
Also, a bit more perf tuning got the first set of test data down to 0.58 seconds.
PS: I’m not normally this paranoid with performance tuning UI related code, but this is big chunk of fairly complicated code that will be used for most of the text that Cantabile needs to display on screen. It needs to be rock solid, fast and not put pressure on the garbage collector.
Tracked down that last 3mb of memory usage, making the new implementation almost 4x faster than the old one (for the second set of test data) and uses 8Kb instead of 240Mb.
I’ve got one more performance experiment I want to try then I’ll be taking a closer look at the line breaking algorithm (but I think it might be ok as is).
Ah, the joys of code optimisation. I still remember the heady days of the late 80s when you really had to squeeze very last drop out of processor performance. Often that meant dropping to assembly language (as high level language compilers were still not brilliant in terms of code efficiency), overlapping integer and floating point unit operations (a floating point multiply might take, for example, 20 clock cycles, during which you could do several integer operations before needing the floating point result), keeping variables in processor registers to avoid unnecessary memory writes, etc. , etc.
I remember demonstrating to a sceptical former boss a “Sobel” convolution edge detection image processing algorithm running over 20 times faster in assembly language compared to the PDP11 Fortran equivalent.
These days, I’ll just buy a faster processor or more memory but there was a certain satisfaction when you got something running on steroids in the old days, so hopefully Brad is feeling the same way right now over this!
So, huge Kudos to what Brad is doing on this area. Sounds like real progress that will benefit Cantabile as a multi-national/language platform (just look at the spread of users on the “where are you from” thread).



 fast !
fast !